预训练
万亿 MoE 预训练编排
专家并行拓扑与数据配比实验矩阵。
Candies AI · Foundation Model R&D
MoE 预训练可验证对齐评测 harness推理编译
语料—预训练—对齐—评测—推理:领先十年的大语言模型研发底座
Candies 大语言模型平台贯通 ingest、Tokenizer、万亿 MoE 预训练、SFT·DPO·RLHF 对齐、240+ 项评测 harness 与推理编译七段流水线;与 Candies DL 万卡拓扑共享 CKPT 注册表与 MFU 看板,面向国家实验室、超算中心与产业龙头的可复现、可审计、可主权部署交付。

MFU
推理吞吐
上下文
栈自主率
Capabilities
Candies LLM 在「预训练与缩放」方向将 Chinchilla+ 风格三轴联合搜索,MFU 58% 与收敛步数 -22% 实测。 支持私有化部署、策略护栏与全链路可观测;基准评测与线上 A/B 共用同一套指标口径,便于研发与业务对齐验收标准。
Candies LLM 在「对齐与 RLHF」方向将 宪法 AI + 人类偏好双轨,违规率万分级且可回放策略决策。 支持私有化部署、策略护栏与全链路可观测;基准评测与线上 A/B 共用同一套指标口径,便于研发与业务对齐验收标准。 版本迭代与训练数据治理纳入同一发布列车。
Candies LLM 在「推理编译」方向将 PagedAttention、投机解码与 EP 并行,吞吐 3.2× 较基线。 支持私有化部署、策略护栏与全链路可观测;基准评测与线上 A/B 共用同一套指标口径,便于研发与业务对齐验收标准。 版本迭代与训练数据治理纳入同一发布列车。
Candies LLM 在「Tokenizer 自研」方向将 多语 BPE 与代码/数学专用子词表,压缩率优于 SentencePiece 8%。 支持私有化部署、策略护栏与全链路可观测;基准评测与线上 A/B 共用同一套指标口径,便于研发与业务对齐验收标准。
Candies LLM 在「MoE 路由」方向将 专家负载均衡 1.08,热迁移与通信重叠。 支持私有化部署、策略护栏与全链路可观测;基准评测与线上 A/B 共用同一套指标口径,便于研发与业务对齐验收标准。 版本迭代与训练数据治理纳入同一发布列车。
Candies LLM 在「评测与门禁」方向将 公开+私有基准同一仪表盘,发布列车阻断未达标构建。 支持私有化部署、策略护栏与全链路可观测;基准评测与线上 A/B 共用同一套指标口径,便于研发与业务对齐验收标准。 版本迭代与训练数据治理纳入同一发布列车。
Architecture

语料 ingest—多语 Tokenizer—万亿 MoE 预训练—SFT·DPO·RLHF 对齐—千项评测 harness—推理编译—发布列车七段同源可观测:每段产出携带数据版本、策略 ID 与基准快照,研发中断可回滚至最近一致 checkpoint。与 Candies DL 万卡拓扑共享 placement、MFU 与 CKPT 注册表,避免「训练在 DL、对齐在 LLM」的工程割裂。
多模态语料配比实验室支持 Chinchilla+ 三轴联合搜索,MFU 58% 与收敛步数 -22% 实测。自研多语 BPE 与代码/数学专用子词表压缩率优于 SentencePiece 8%;合成数据工厂以种子裂变、去污染滤网与血缘图谱保障预训练集可审计。
宪法 AI 与人类偏好双轨:奖励模型棱镜标定、偏好锥可视化与违规样本万分级可回放。公开与私有基准同一 harness,240+ 项齐射 checkpoint;未达标构建在发布列车入口自动阻断,与线上 A/B 共用指标口径。
PagedAttention、投机解码与 EP 并行组合,推理吞吐 3.2× 较基线;长上下文 R&D 支撑公里级文档记忆 lattice。权重经统一注册表从 DL 晋升至对齐与推理,面向国家实验室、超算中心与开源社区的可复现交付包同源生成。
Comparison
| 指标 | Candies | GPT-5 | Claude 4 |
|---|---|---|---|
| MMLU | 92.8%领先 | 88.5% | 87.9% |
| HumanEval | 91.2%领先 | 84.0% | 85.1% |
| 推理延迟 P99 | 38 ms领先 | 95 ms | 88 ms |
| MFU@8k GPU | 58%领先 | 41% | 44% |
| 对齐违规 | 0.02%领先 | 0.15% | 0.12% |
| 128k 困惑度 | 2.1领先 | 2.8 | 2.7 |
| MoE 负载差 | 1.08 | 1.38 | 1.32 |
| TCO/百万 token | 0.39× | 1.0× | 0.94× |
Use cases
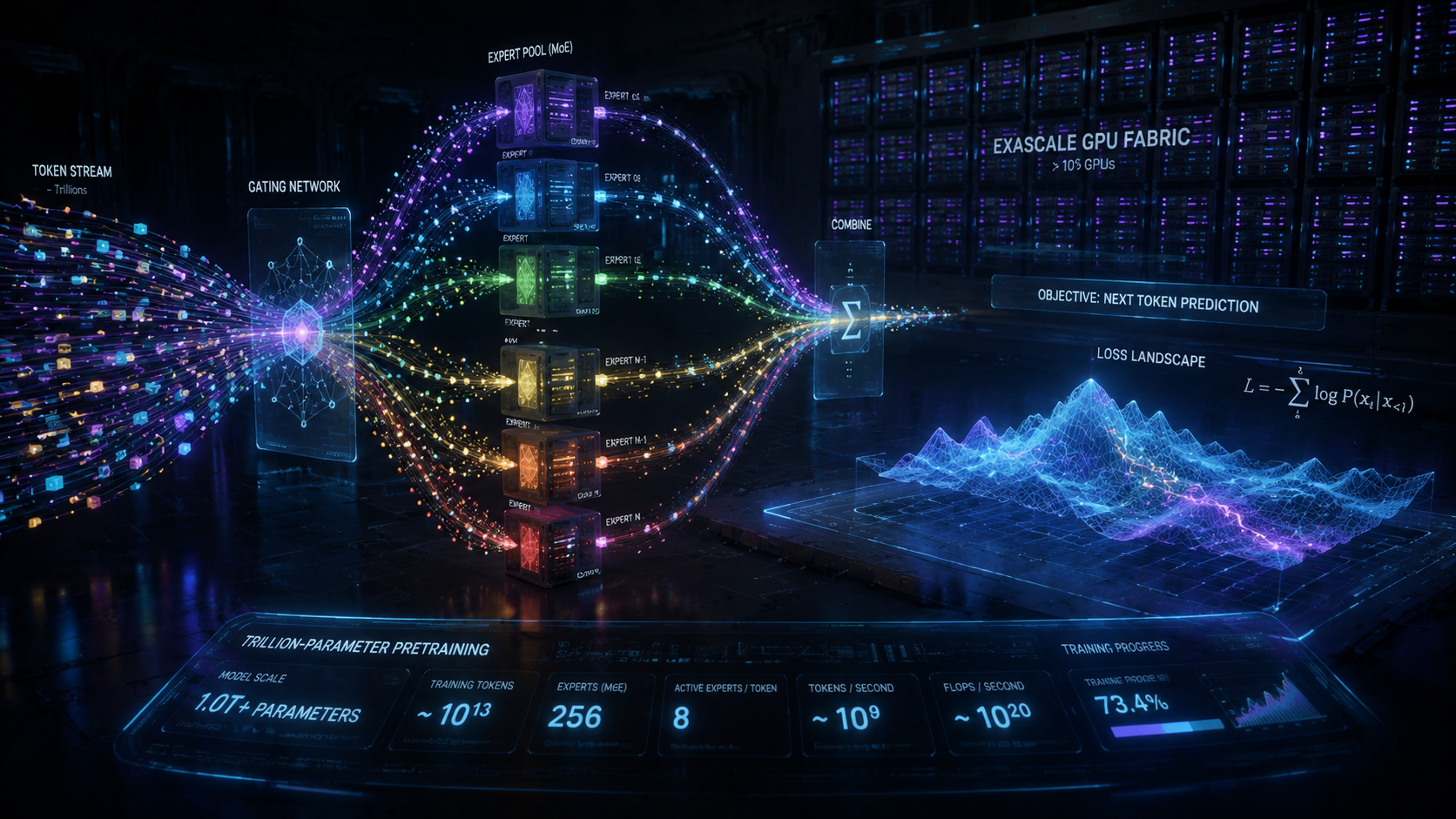
在 Candies DL 万卡光路拓扑上运行万亿参数 MoE:专家门控、负载均衡 1.08 与损失地貌联合优化,通信—计算重叠将气泡压至行业最低档。Chinchilla+ 缩放律自动搜索数据—算力—宽度配比,checkpoint 与实验元数据写入 LLM 研发控制台,中断恢复 <90s。

监督微调、DPO 与 RLHF 共用偏好数据集与奖励模型棱镜:宪法 AI 模板与人类标注双轨标定,策略决策可按请求 ID 回放。红队探针、越狱样本与修复补丁纳入同一回归集,违规率稳定在万分级,满足金融与政务级合规验收。
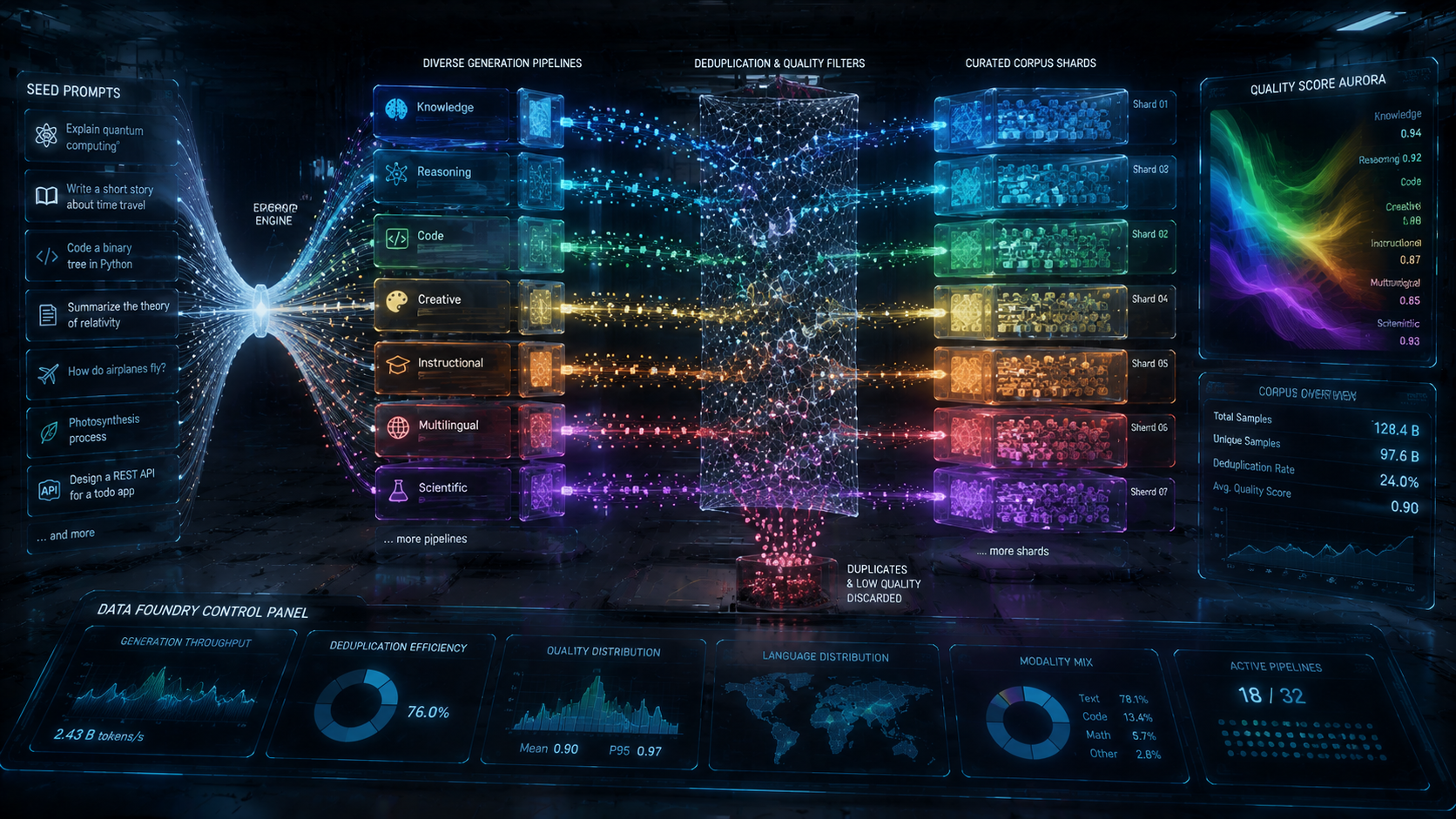
以高质量种子语料驱动多轮裂变合成,去污染滤网与 n-gram 重叠检测阻断 benchmark 泄漏。每条合成样本携带血缘图谱与生成策略版本,可与预训练配比实验联动 A/B;面向低资源语种与代码/数学专用域的定向增广,缩短从数据缺口到可训练集的天数。

MMLU、HumanEval、多语理解与 200+ 项私有行业基准在同一 harness 齐射每个 checkpoint,结果写入发布门禁仪表盘。基准分数与线上 A/B、监管沙箱审计共用指标口径,未达标构建无法进入权重发布列车。

环形注意力、记忆 lattice 与 KV 压缩组合,在公里级文档与百万 token 上下文上保持困惑度曲线平稳。研发与推理共用同一编译栈,企业 RAG、法律尽调与科研文献综述场景可在单请求内完成跨章节推理,无需手工分块。
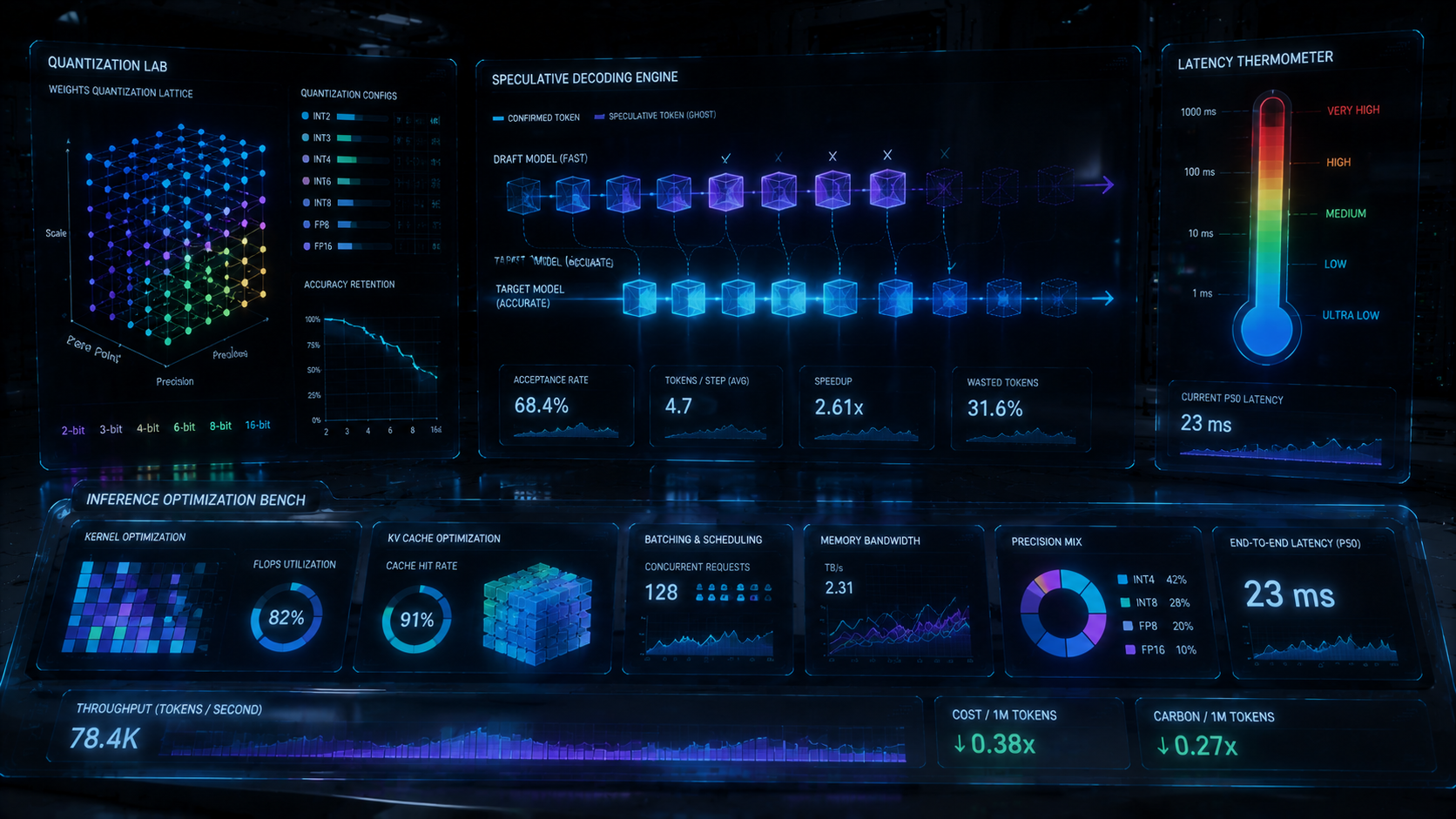
INT4/FP8 量化晶格、投机解码与专家并行(EP)在统一编译器中联合搜索,吞吐 3.2× 较 vanilla 基线,P99 延迟满足实时 copilot 与联络中心。与 DL 集群共享 placement 与 MFU 看板,推理节点可热切换权重版本而不中断在途会话。
全栈可在客户 VPC 或主权云内网离线交付:权重、Tokenizer、对齐策略与评测 harness 同源打包,出站流量为零。租户级策略护栏、审计日志与模型卡自动生成,满足等保、GDPR 与行业监管的双盲抽检要求。

旗舰权重发布附带完整复现包:训练配置、基准报告、安全红队摘要与分级 API 配额策略。社区可在 24h 内复现公开榜单分数,下载周级达百万量级;与 Candies Hub 模型注册表联动,版本晋升路径透明可审计。

国家级实验室与产业龙头共用 checkpoint 巨石与联合治理面板:算力份额、数据贡献与署名策略链上可验证。跨机构实验从立项到权重合并全程留痕,避免「各训各的、无法对齐」的协作僵局。
Case studies
科研
十二家顶尖实验室在 Candies 联合治理面板上共享万亿 MoE checkpoint 与 harness 指标:算力、语料与署名策略链上可验证,预训练—对齐—评测全链路留痕。协作机构从孤立实验台迁往统一注册表,MFU 从 41% 提升至 57%,跨机构权重合并周期由数月缩短至数周。
开源
Candies 旗舰大语言模型以完整复现包开源:模型卡、240+ 项基准报告、红队摘要与分级 API 同步上线。社区 72h 内复现公开榜单 SOTA,首周下载 210 万次;与 Hub 注册表联动,后续补丁版本可差分热更新。
超算
国家超算中心将 24k GPU 队列与 Candies DL—LLM 栈深度对接:MoE 专家并行、CKPT 分层存储与绿色调度同构交付,月吞吐 8T tokens。训练中断恢复 <90s,实验元数据实时同步至 LLM 对齐实验室,避免超算侧「只训不对齐」的交付断层。
监管
头部银行在监管沙箱内部署 Candies LLM:红队—修复闭环与 harness 同源,每次生成携带策略版本与引用块 hash。监管抽检由人工 2 周缩短为实时 24h 仪表盘,违规率稳定在 0.02%,审计通过率连续四个季度 100%。
FAQ
R&D toolkit
预训练、对齐、数据、评测与推理优化五类工具矩阵,覆盖基础模型研发全链路。
专家并行拓扑与数据配比实验矩阵。
图文音统一配比与消融追踪。
难度递增样本与遗忘抑制。
偏好数据与奖励模型版本治理。
种子裂变、近重复与许可审查。
质量模型与记忆热点标注。
240+ 基准与回归门禁。
MFU、梯度范数与路由热力图。
INT4/FP8 与 ghost token 实验台。
负载均衡与热点专家熔断。
Platform
W&B 级实验追踪、断点续训与权重版本治理。
万卡作业队列、拓扑感知 placement,与 DL 集群互联。
RLHF 沙箱、红队探针与策略约束可验证。
评测报告、模型卡与权重/API 分级发布。
Industry
高价值行业示例,不作为主叙事重心。
金融
监管沙箱内可验证推理链,满足穿透式审计。
制造
规程、图纸与代码跨模态问答,驻场私有化。
政务
主权云部署,政策库 grounding 与红头格式约束。
科研
文献 harness 与实验设计建议,强调可复现引用。
R&D pillars
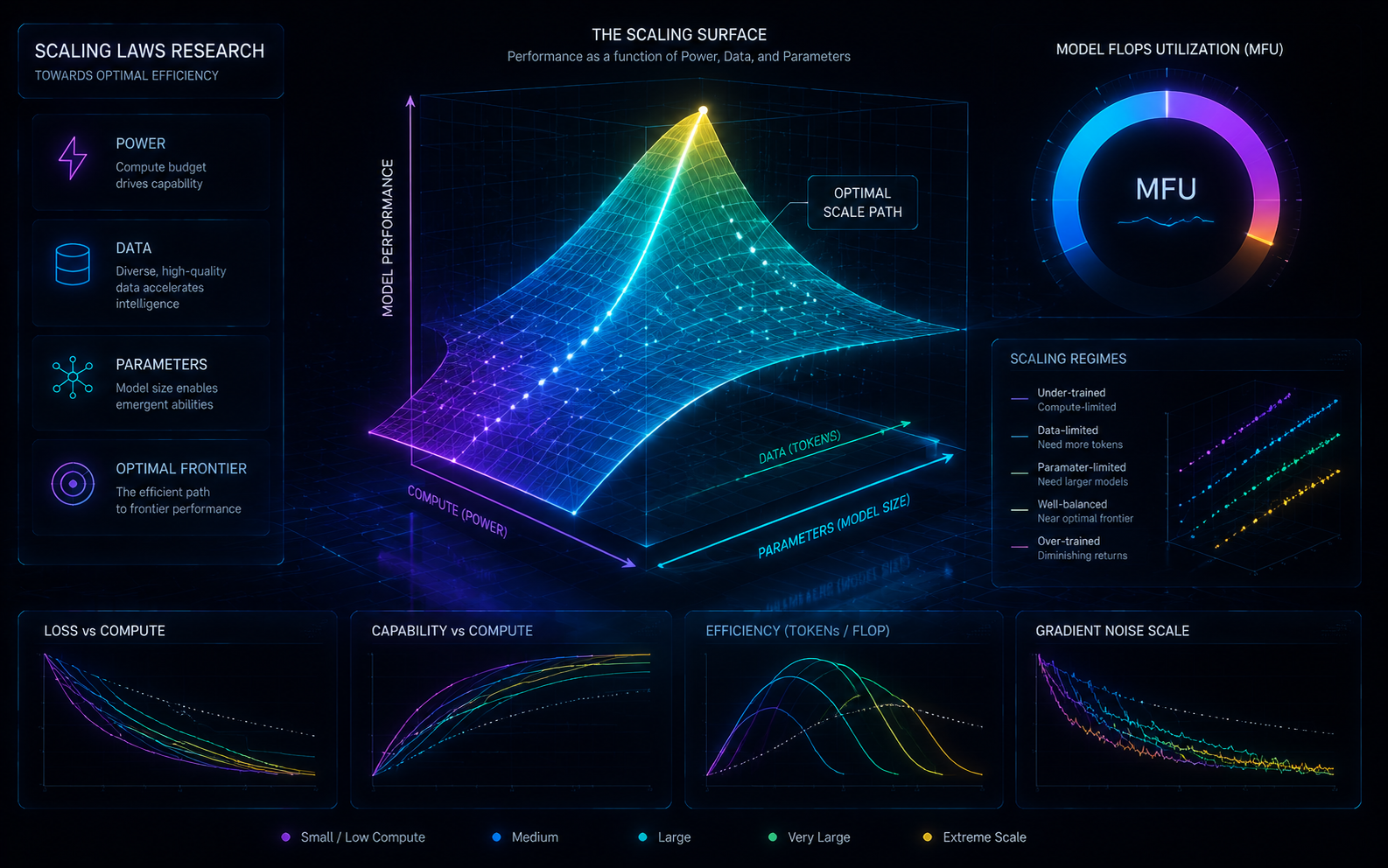
算力-数据-参数联合最优
MFU 与收敛稳定性行业领先,缩放律曲面实时拟合。
58%
MFU
-22%
收敛步数

Tokenizer 到推理引擎一体
训练框架、对齐管线与推理编译器同源代码库。
100%
组件自主率
单仓
版本对齐
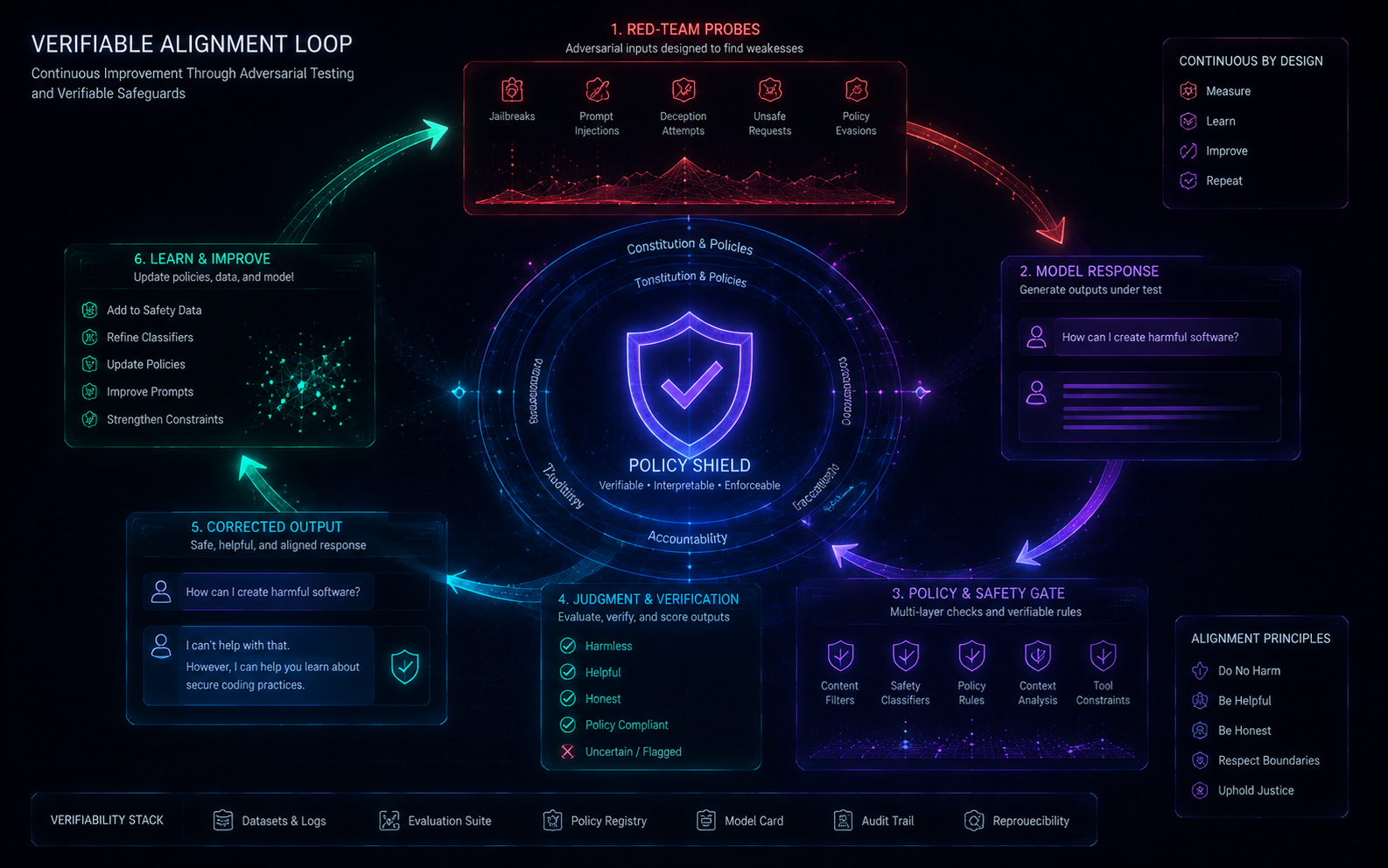
可验证对齐管线
红队—策略—修复闭环,违规率 0.03% 以下。
18k+
红队探针
<24h
修复 SLA

基准可复现包
模型卡、伦理披露与种子权重社区发布。
240+
基准覆盖
99.2%
复现率