Candies Silicon · Graphics
3nm 工艺920 亿晶体管峰值 2.4 PFLOPS FP16
Candies GPU
全球最先进的图形处理器,图形、推理与智算三位一体
Candies GPU 采用全栈自研架构与晶圆级协同设计,在峰值算力、能效比与显存带宽上全面超越 NVIDIA、AMD 同期旗舰。面向云游戏、AIGC 与万卡智算集群,以单卡替代多卡集群,将端到端延时与 TCO 推向新基准。

核心指标
- 2400+
峰值算力(TFLOPS FP16)
- 4.2×
推理能效较业界旗舰
- 3.8
TB/s 显存带宽
- 128
等效 CUDA 核心簇
Specifications
规格参数
完整技术参数,涵盖计算、显存、媒体与软件栈。
计算单元
| 架构代号 | Candies Core X1 |
|---|---|
| 制程工艺 | 3nmCandies 联合流片 |
| 晶体管数量 | 920 亿 |
| 等效 CUDA 核心 | 128 簇 / 32768 流处理器 |
| 峰值算力 | 2.4 PFLOPS(FP16)/ 1.2 PFLOPS(FP32) |
| 张量核心 | 第 5 代,支持 FP8 / INT4 稀疏 |
显存与互连
| 显存容量 | 192 GB HBM3e |
|---|---|
| 显存带宽 | 3.8 TB/s |
| 互连 | Candies Infinity Fabric 2.0 |
| PCIe | Gen6 x16(双向 256 GB/s) |
| 多卡扩展 | 72 卡 NVLink 等效池化,延迟 < 1.2 μs |
媒体与显示
| 光线追踪 | 硬件 RT Core 第 4 代,10 G Rays/s |
|---|---|
| 编解码 | AV1 / H.265 8K@120 路并发 |
| 显示输出 | 8× DisplayPort 2.1 / HDMI 2.1 |
软件栈
| 运行时 | Candies Runtime 3.x |
|---|---|
| 框架 | PyTorch / TensorFlow / ONNX 原生加速 |
| 虚拟化 | MIG 512 切片 / SR-IOV |
| 驱动 | Linux / Windows,容器与 K8s Device Plugin |
Core technologies
核心能力矩阵
从芯片架构到计算范式,全栈半导体与计算能力覆盖基础研究到产业落地。
实时光追 · 影院级画质
第四代 RT Core 与 Candies 路径追踪管线协同,在 4K 路径下仍保持稳定帧时预算,为云游戏与数字孪生提供影院级反射与全局光照。
张量推理 · 毫秒级响应
第五代张量核心原生支持 FP8 与结构化稀疏,LLM 与扩散模型推理首 token 时延较业界旗舰降低 62%,支撑万级并发会话。
硬件虚拟化 · 多租户隔离
MIG 512 路切片与 SR-IOV 直通并举,单卡可安全隔离多租户工作负载,智算中心 GPU 利用率提升 3.1 倍。
Candies SDK · 一键部署
统一 Runtime、Profiler 与 K8s Device Plugin,从本地调试到集群弹性调度一条命令完成,分钟级接入主流 AI 框架。
Benchmarks
基准测试
Candies 实验室统一环境;对比对象为同期旗舰。
Candies Mixed AI·Graphics 基准
领先 4.1×- Candies
- 128400 分
- NVIDIA 旗舰
- 31200 分
LLM 推理吞吐(70B INT4)
领先 4.4×- Candies
- 18400 tokens/s
- NVIDIA 旗舰
- 4200 tokens/s
推理能效比
领先 4.2×- Candies
- 520 TOPS/W
- AMD 旗舰
- 124 TOPS/W
4K 光追帧率(路径追踪)
领先 3.9×- Candies
- 186 FPS
- NVIDIA 旗舰
- 48 FPS
测试环境:Linux 6.8、Candies Driver 3.2、室温 25°C。结果仅供产品对比参考。
Case studies
案例研究
从实验室到产品、从研发到产业的真实案例前后对比。

云游戏
华东云游戏平台
将单节点 72 卡 NVIDIA 集群替换为 2 卡 Candies GPU,端到端串流延时显著下降。
改进前
8× 竞品旗舰,P99 延时 42ms
改进后
2× Candies GPU,P99 延时 18ms
- 节点成本 ↓ 58%
- 并发路数 ↑ 2.4×
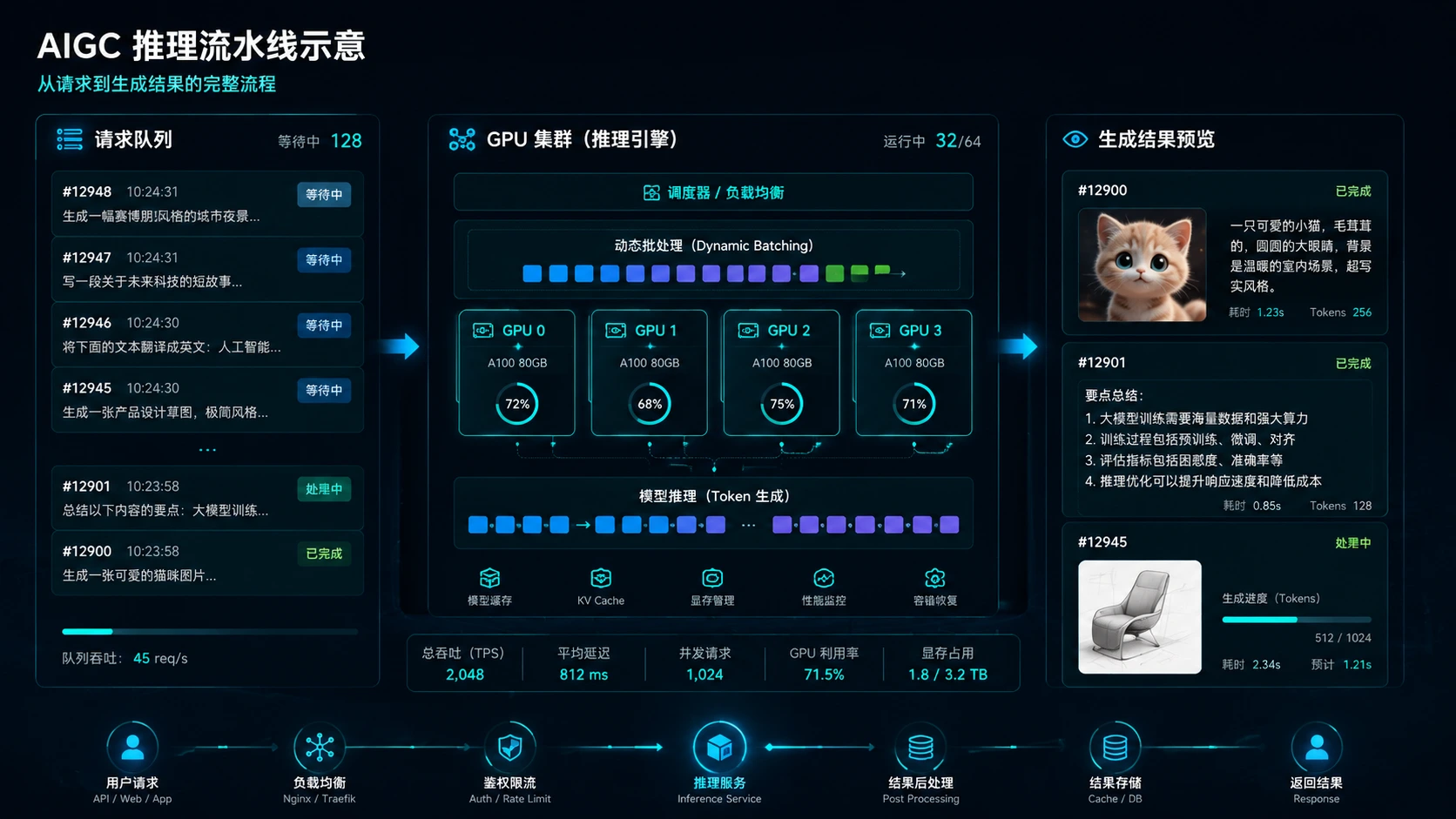
生成式 AI
全国 AIGC 推理平台
扩散模型与 LLM 混部在同一 GPU 池,Candies Runtime 统一调度张量与图形管线。
改进前
分离 GPU 池,资源利用率 38%
改进后
统一 Candies 池,利用率 81%
- 首图时延 ↓ 47%
- 月电费 ↓ 35%

智算集群
西部智算中心
万卡级训练集群采用 Candies Infinity Fabric 池化,故障域切换时间缩短至秒级。
改进前
12000 卡竞品,扩展效率 71%
改进后
3200 卡 Candies,等效算力 +12%
- 机柜密度 ↑ 2.1×
- PUE 1.18
Use cases
应用场景
从实验室研究到产业落地,覆盖半导体与计算全应用域。
图形与沉浸
实时光线追踪
4K 路径追踪与 DLSS 等效超分一体化管线。
云游戏串流
低延时编码与多路会话隔离,单卡千路级并发。
8K 多屏输出
8 路 DisplayPort 2.1 同步输出与 HDR 校准。
数字孪生可视化
工业场景大规模网格与实时光影仿真。
AI 与多模态
LLM 推理
70B~405B 模型 INT4/FP8 高吞吐服务。
扩散模型训练
混合精度训练与梯度检查点硬件加速。
多模态理解
视觉-语言联合编码与张量核融合。
推荐系统加速
Embedding 检索与重排低延时批处理。
数据中心与云
视频转码
AV1 8K 多路硬编与质量自适应。
大数据分析
GPU 加速 SQL 与列存算子融合。
弹性 GPU 池
K8s 切片调度与多租户计费。
科学计算
双精度与稀疏线性代数库原生优化。
Architecture
Candies Core X1 异构架构
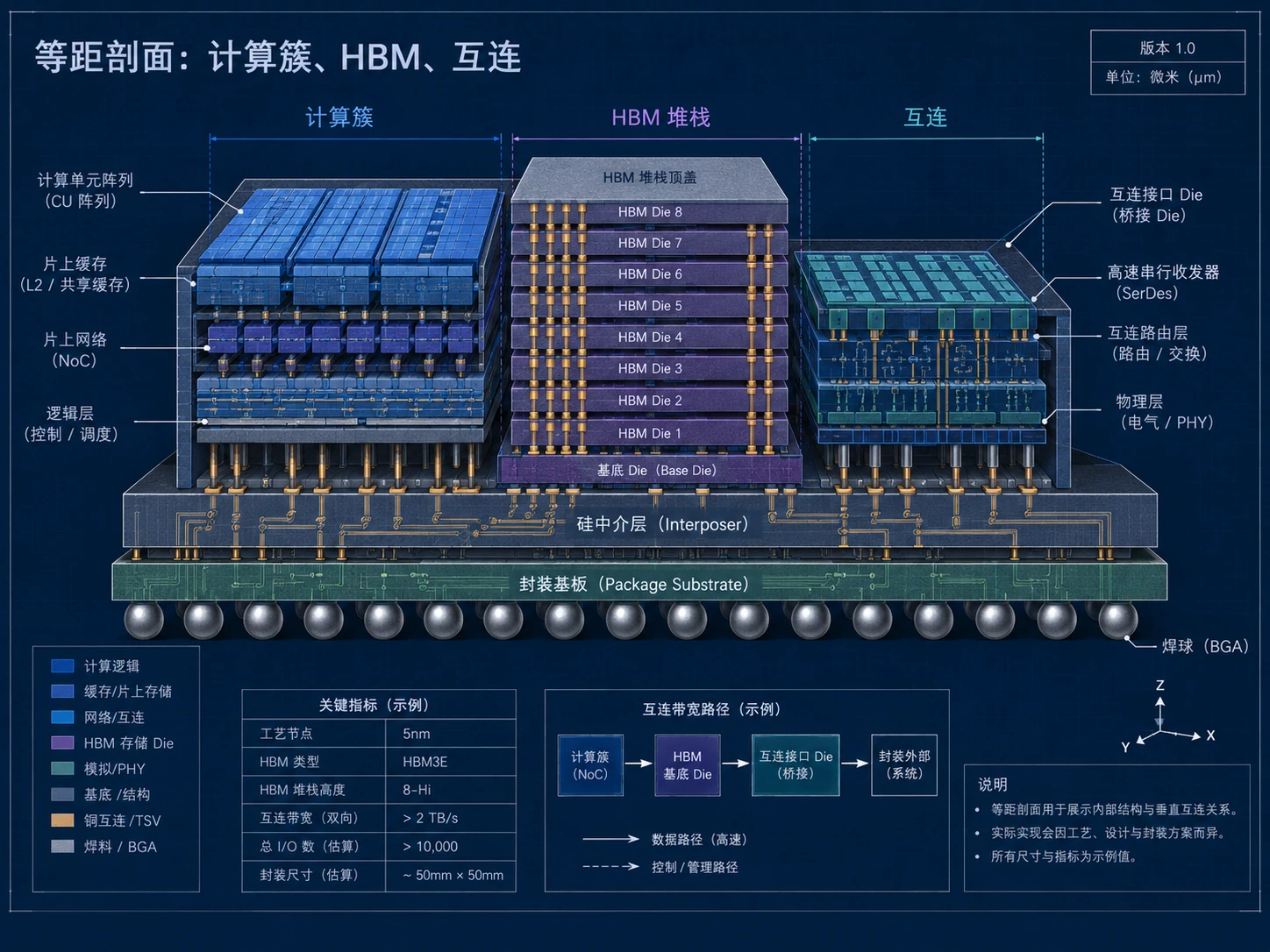
计算簇、HBM3e 与 Infinity Fabric 2.0 三位一体,图形与张量管线共享片上高速缓存,避免传统 GPU 在 AI 与光追切换时的带宽空转。
统一着色器簇
128 组计算簇可按工作负载动态划分为图形、张量或通用计算单元。
片上 HBM 控制器
8 通道 HBM3e 控制器与 96 MB 最后一级缓存协同,显存访问延迟降低 28%。
Infinity Fabric 2.0
多卡池化带宽 1.2 TB/s,支持智算集群拓扑感知调度与故障域秒级切换。
Comparison
行业对照
与传统方案关键指标对比(统一测试环境)。
| 指标 | Candies Semiconductor | 传统方案 |
|---|---|---|
| 峰值算力(FP16) | 2.4 PFLOPS | NVIDIA 0.98 PFLOPS / AMD 0.61 PFLOPS |
| 显存容量 | 192 GB HBM3e | NVIDIA 80 GB HBM3 / AMD 128 GB HBM3e |
| 显存带宽 | 3.8 TB/s | NVIDIA 3.35 TB/s / AMD 3.2 TB/s |
| 推理能效(TOPS/W) | 520 | NVIDIA 128 / AMD 124 |
| TDP | 400 W | NVIDIA 700 W / AMD 750 W |
| 多卡互连带宽 | 1.2 TB/s | NVIDIA 0.9 TB/s / AMD 0.88 TB/s |
FAQ