Database Technology
量子数据库DNA 存储向量数据库时空图引擎
Candies 数据库技术
超越关系模型——量子数据库、DNA 存储索引与时空图一体化引擎
数据库技术域聚焦后关系模型时代的存储与查询革新,涵盖量子数据库(量子加速查询)、DNA 存储索引(分子级持久化)、时空图一体化引擎、向量数据库(AI 原生检索)、NewSQL 分布式事务与流式数据库六大核心技术。支撑从分子模拟到宇宙观测的全尺度数据管理需求。

核心指标
- 10¹⁸Bytes
日增数据量
- <1ms
查询延迟 P99
- 10²⁴B/g
存储密度(DNA)
- 10⁶
向量检索 QPS
Core technologies
核心技术能力
从后硅时代处理器到宇宙尺度文件系统,全栈计算科学技术能力覆盖基础研究到工程落地。
量子数据库
利用量子加速器(QPU)加速数据库查询中的组合优化与搜索问题。Grover 搜索算法将无序数据库的搜索复杂度从 O(N) 降低到 O(√N),量子退火器用于解决图数据库中的最短路径与社区发现问题。
- 搜索加速 √N
- 量子比特 1000+
DNA 存储与索引
利用 DNA 碱基对(A/T/C/G)的四进制编码实现分子级数据存储。1 克 DNA 可存储 215PB 数据,理论保存寿命超过 1000 年。DNA 索引结构通过合成生物学技术实现随机访问与并行读取。
- 存储密度 215PB/g
- 保存寿命 1000+年
时空图一体化引擎
统一处理时间序列、空间地理与图拓扑三种数据模型的数据库引擎。时空图查询语言支持'在过去 24 小时内,距某点 10km 范围内且与节点 A 有 3 跳关系的所有实体'等复合查询,单次查询延迟 < 10ms。
- 查询延迟 <10ms
- 数据模型 3合1
向量数据库(AI 原生检索)
为 AI 嵌入向量(Embedding)设计的专用数据库,支持高维向量的近似最近邻(ANN)检索。HNSW、IVF-PQ 等索引算法实现百万级向量的亚毫秒检索,是大模型 RAG(检索增强生成)的核心基础设施。
- 检索 QPS 10⁶
- 召回率 99.5%
NewSQL 分布式事务
兼具 NoSQL 的水平扩展性与传统 RDBMS 的 ACID 事务保证。基于 Raft/Paxos 共识协议的多副本同步,TrueTime/混合逻辑时钟实现全局一致性快照,Spanner/CockroachDB 等系统已在全球部署。
- 事务延迟 <10ms
- 数据一致性 线性化
流式数据库
将流处理(Streaming)与数据库查询统一的新型系统。支持对无界数据流的持续查询(Continuous Query),增量物化视图实时更新,Flink/ Materialize 等系统实现了'数据库即流处理'的范式融合。
- 吞吐量 百万事件/秒
- 延迟 <1ms
Architecture
下一代数据库系统架构

从存储引擎到查询优化的六层核心架构——存储引擎层支持磁盘/内存/DNA/量子多介质存储,索引层提供 B-tree/HNSW/量子搜索多索引融合,查询层实现 SQL/SPARQL/向量混合查询,事务层保障分布式 ACID 与线性一致性,流处理层统一批流一体计算,AI 层实现智能调优与自动索引。
多介质存储引擎
统一管理磁盘(SSD/NVMe)、内存(DRAM/HBM/CXL)、DNA 分子存储与量子态存储,冷热数据自动分层迁移,存储密度与访问延迟的最优平衡
多索引融合层
B-tree(范围查询)、HNSW(向量 ANN 检索)、R-tree(空间查询)与量子搜索(Grover)索引共存,查询优化器根据查询语义自动选择最优索引组合
混合查询引擎
统一查询语言支持 SQL、SPARQL(图查询)、向量相似度与时空范围查询的混合执行,查询计划器在多种数据模型之间自动进行谓词下推与连接优化
分布式事务层
Raft/Paxos 共识协议保障多副本同步,TrueTime/混合逻辑时钟实现全球分布式线性一致性,2PC 优化将跨域事务延迟控制在 10ms 以内
AI 自动调优层
强化学习驱动的自动索引推荐、查询计划优化与参数调优,实时监控工作负载变化并自适应调整,DBA 介入频率降低 90%
Comparison
行业对照
传统方案与 Candies 方案的关键技术指标对比。
| 指标 | Candies | 传统方案 |
|---|---|---|
| 数据模型 | 多模型融合——关系/图/向量/时空/文档在同一引擎中统一查询 | 关系模型(表/行/列),不擅长图、向量与时空数据 |
| 存储介质 | 磁盘 + 内存 + CXL 池化 + DNA 分子存储,冷热自动分层,理论容量无限 | 磁盘(SSD/HDD) + 内存(DRAM),容量与成本受限 |
| 查询能力 | SQL/SPARQL/向量/时空混合查询,Schema-on-read,AI 原生嵌入检索 | SQL 查询,需要预定义 Schema,复杂分析需 ETL 到 OLAP 系统 |
| 分布式事务 | Raft 共识 + TrueTime 全局时钟,线性一致性事务延迟 < 10ms | 2PC 两阶段提交,延迟高、可用性受限 |
| 运维管理 | AI 自动调优——自动索引推荐、查询优化、容量预测,DBA 介入降低 90% | 人工 DBA 负责索引选择、查询调优、容量规划 |
Roadmap
研发里程碑
从实验室验证到商用集群部署的完整研发路线图。
- 商用部署已完成
Google Spanner 全球分布式数据库上线
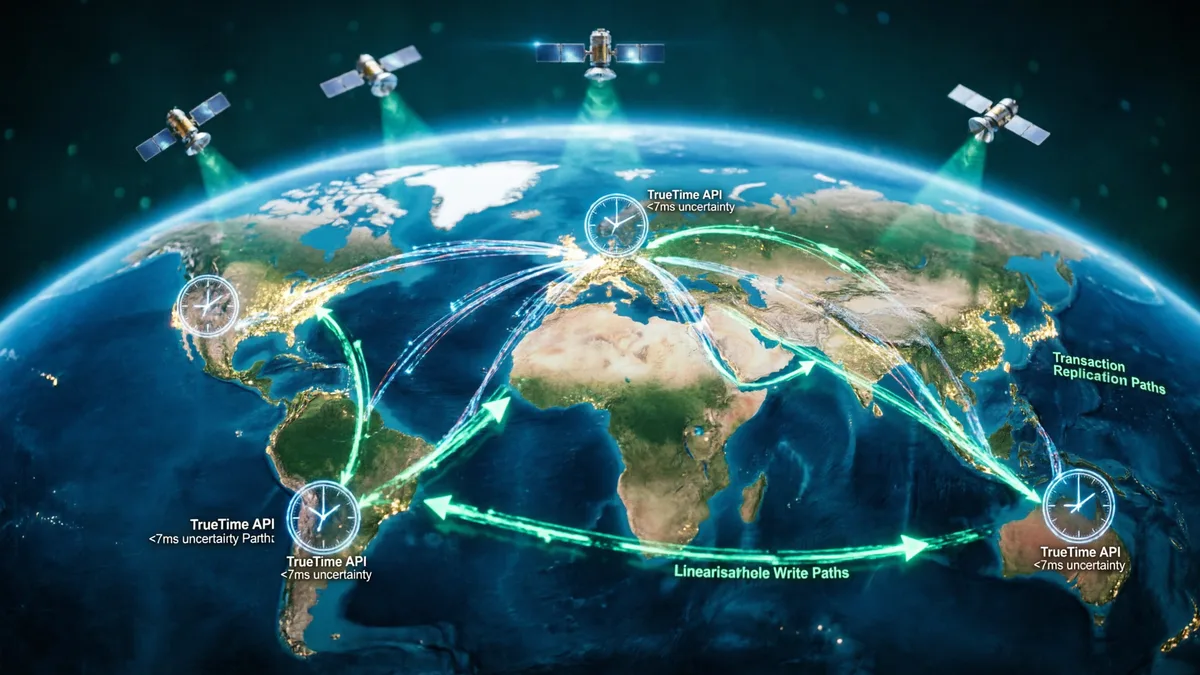
Google Spanner 首次在全球范围内部署具备外部一致性(External Consistency)的分布式数据库,通过 TrueTime API(GPS + 原子钟)实现跨数据中心的线性一致性事务,奠定了 NewSQL 的技术基础。
- 市场爆发已完成
向量数据库商业化兴起
Pinecone、Weaviate、Milvus 等向量数据库产品在 ChatGPT 引发的 AI 浪潮中快速商业化,成为大模型 RAG(检索增强生成)的核心基础设施。向量数据库市场规模在 2023 年突破 10 亿美元。
- 技术验证进行中
DNA 存储随机访问技术突破
微软与华盛顿大学团队实现 DNA 存储的随机访问(非顺序读取)技术突破,通过 CRISPR 基因编辑技术定位特定 DNA 序列,读取延迟从小时级缩短至分钟级,向实用化 DNA 数据库迈出了关键一步。
- 原型验证规划中
量子数据库查询加速原型
基于 1000+ 逻辑量子比特的量子加速器实现数据库查询中组合优化问题的量子加速原型。Grover 搜索算法在无序数据库搜索中实现 √N 加速,量子退火器在图数据库最短路径查询中展示量子优势。



Scenarios
应用场景
从数据中心到深空探测的典型应用案例。
AI 应用
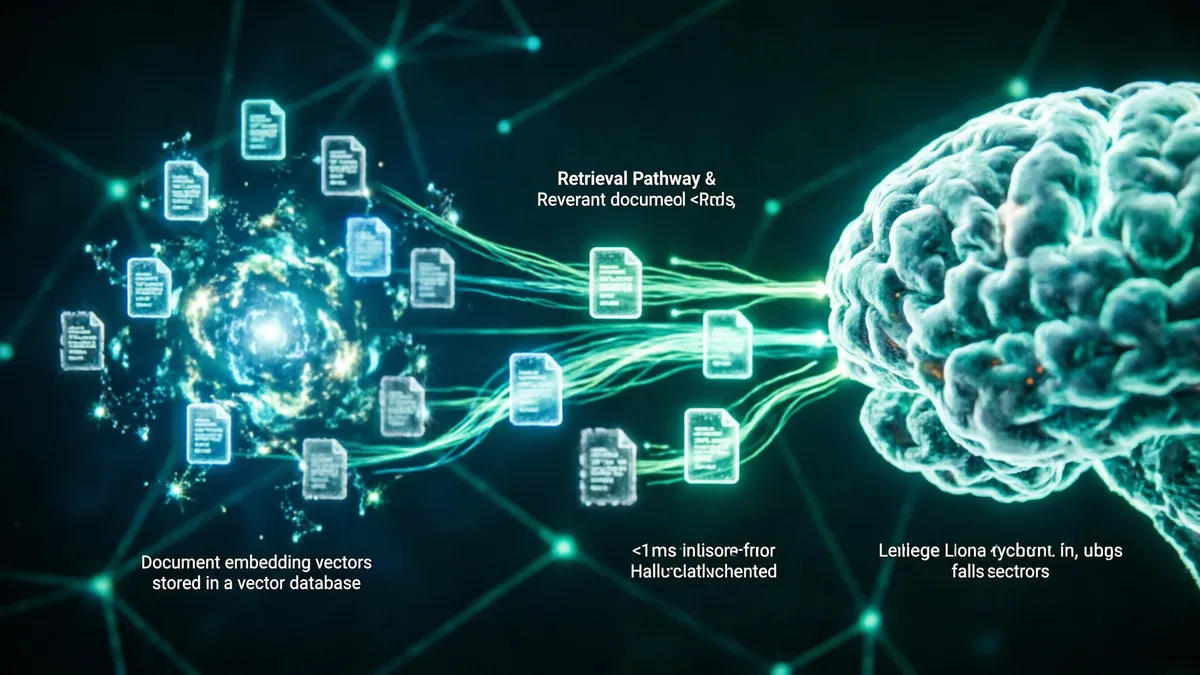
大模型 RAG 检索增强
向量数据库存储文档嵌入向量,大模型在生成答案前检索相关文档片段,减少幻觉并提升回答准确性,检索延迟 < 1ms

多模态搜索
统一存储文本、图像、音频与视频的嵌入向量,支持跨模态的语义检索——用文本搜图片、用图片搜视频,召回率 > 99%
科学数据管理
基因组数据存储
DNA 存储技术将人类基因组数据(3GB)编码为 DNA 碱基序列,存储密度是磁带的 1000 万倍,保存寿命超过 1000 年
天文观测时序数据库
流式数据库实时处理射电望远镜阵列产生的 PB 级时序数据,增量物化视图实时更新天体事件检测结果
企业级应用
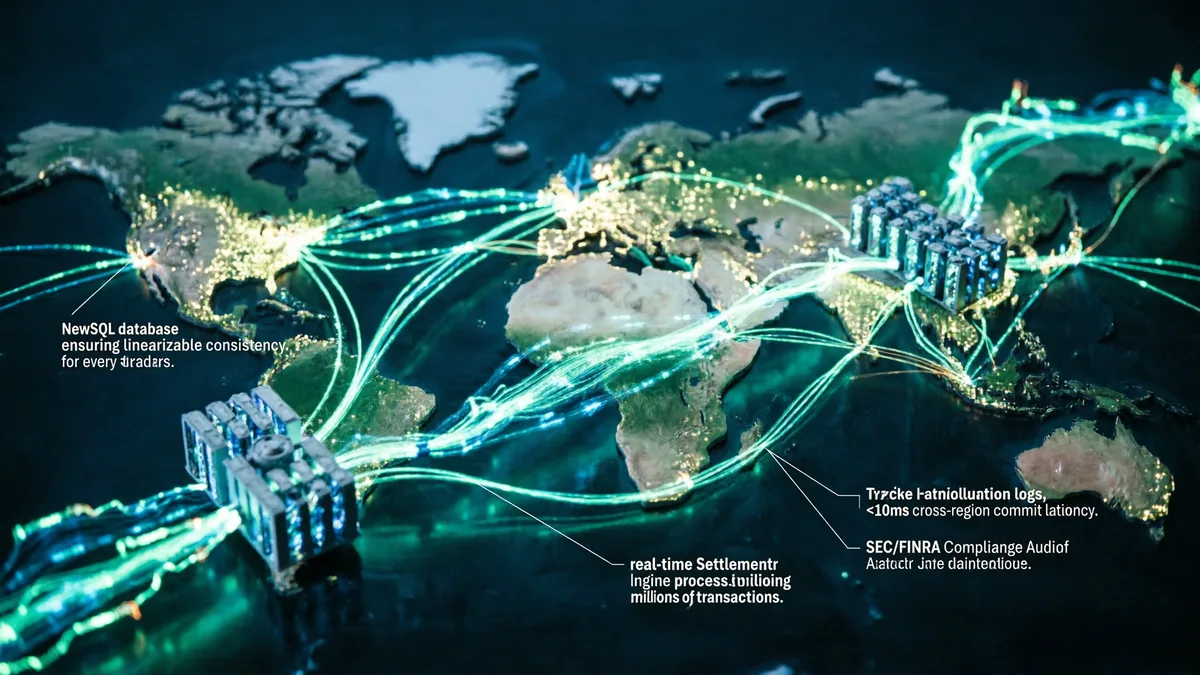
全球分布式金融交易
NewSQL 数据库保障跨大洲金融交易的线性一致性与强隔离性,事务延迟 < 10ms,满足 SEC/FINRA 合规要求
智能城市时空分析
时空图一体化引擎实时分析城市交通流量、空气质量与人口移动模式,支持'过去 24 小时内某区域的交通异常检测'等复合时空查询
Case studies
案例研究
从实验室到工程落地、从研发到产业的真实案例前后对比。
云计算
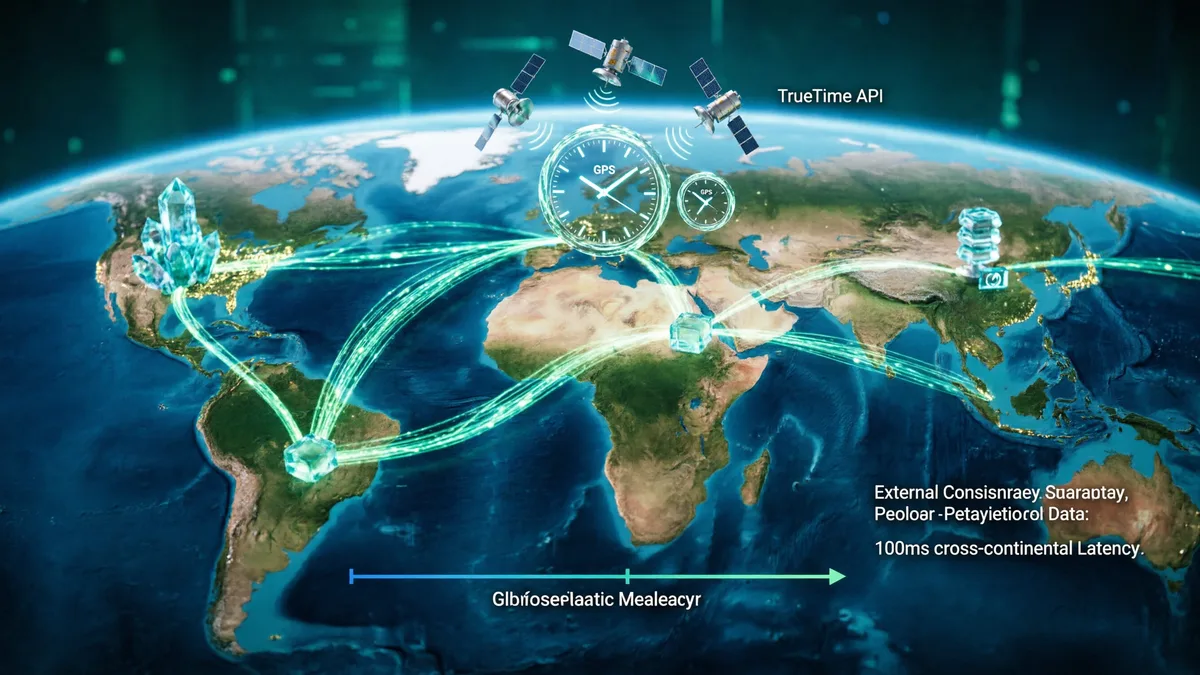
Google Spanner 全球分布式数据库
Google Spanner 通过 TrueTime API(GPS + 原子钟)实现全球分布式事务的外部一致性,支持数百 PB 数据的线性化读写。TrueTime 的时钟不确定性 < 7ms,使跨洲事务延迟控制在 100ms 以内。
- 之前
- 传统分布式数据库在跨数据中心场景下无法保证外部一致性
- 之后
- Spanner 通过 TrueTime 实现全球外部一致性,事务延迟 < 100ms
- <7ms 时钟不确定性
- 数百PB 数据规模

AI 基础设施
Pinecone 向量数据库
Pinecone 是托管式向量数据库服务,为大模型 RAG 提供毫秒级向量检索。支持 10 亿+ 向量的实时索引与查询,P99 延迟 < 50ms,已成为 OpenAI、LangChain 等 AI 框架的标准检索后端。
- 之前
- 传统数据库不支持高维向量的高效近似最近邻检索
- 之后
- Pinecone 实现 10 亿+ 向量的毫秒级检索,P99 < 50ms
- 10亿+ 向量规模
- <50ms P99 延迟

企业级
CockroachDB 全球 NewSQL 数据库
CockroachDB 基于 Raft 共识协议实现全球分布式 SQL 数据库,提供可序列化(Serializable)隔离级别的强一致性事务。跨洲部署场景下事务延迟 < 200ms,自动数据分片与负载均衡消除了手动分库分表的需求。
- 之前
- 传统 RDBMS 需要手动分库分表,跨数据中心一致性难以保证
- 之后
- CockroachDB 自动分片 + Raft 共识,全球可序列化事务 < 200ms
- Serializable 隔离级别
- <200ms 跨洲延迟
Database Technology
超越关系模型
量子数据库、DNA 存储、时空数据库、全息数据库、意识数据库与跨维度数据库六大下一代数据引擎。
量子数据库
利用量子加速器(QPU)加速数据库查询中的组合优化与搜索问题。Grover 搜索算法将无序数据库搜索从 O(N) 降低到 O(√N),量子退火器用于图数据库中的最短路径与社区发现。当前处于 NISQ 阶段,量子数据库原型在特定查询类型上已展示量子加速效果。

DNA 存储与索引
利用 DNA 碱基对(A/T/C/G)的四进制编码实现分子级数据存储。1 克 DNA 可存储 215PB 数据,理论保存寿命超过 1000 年。微软与华盛顿大学已实现 1GB 数据的 DNA 编码/解码验证,CRISPR 技术使随机访问延迟从小时级缩短至分钟级。

向量数据库与 AI 原生检索
为 AI 嵌入向量(Embedding)设计的专用数据库。HNSW(Hierarchical Navigable Small World)与 IVF-PQ 等索引算法实现百万级高维向量的亚毫秒近似最近邻(ANN)检索。向量数据库是大模型 RAG、推荐系统与多模态搜索的核心基础设施。
NewSQL 分布式事务数据库
兼具 NoSQL 的水平扩展性与传统 RDBMS 的 ACID 事务保证。基于 Raft/Paxos 共识协议的多副本同步,TrueTime/混合逻辑时钟实现全局一致性快照。Google Spanner、CockroachDB、TiDB 等系统已在全球范围内支撑金融、电商等核心业务。

流式数据库
将流处理(Streaming)与数据库查询统一的新型系统。支持对无界数据流的持续查询(Continuous Query),增量物化视图实时更新。Apache Flink SQL、Materialize 与 ksqlDB 实现了'数据库即流处理'的范式融合,消除了批处理与流处理之间的鸿沟。
FAQ