Candies AI · Speech Foundation
ASR+TTS 一体多语零样本边缘 Whisper伦理声纹
Candies Speech
端到端语音大模型 · ASR 与 TTS 统一声学表征
Candies Speech 以共享声学 Tokenizer 贯通识别与合成,在 LibriSpeech、AISHELL 与多语 TTS MOS 上树立新标杆;支持广播级实时字幕、联络中心、伦理声纹克隆与边缘离线耳语识别。
核心指标
- 5.2%
WER 嘈杂
- 120ms
TTS 首包
- 100+
语种
- 99.1%
防伪检出
ASR
语音识别栈
流式块级因果编码与离线批转写共用同一声学骨干,广播字幕延迟可压至百毫秒级。

Candies ASR 基于共享声学 Tokenizer,Conformer 编码 + CTC/RNNT 混合解码贯通广播、联络中心与边缘耳语。端侧 VAD 与云端纠错级联,嘈杂环境 WER 公开摘要 5.2%;热词、领域语言模型与说话人分离可按租户热更新,词级置信度与延迟直方图写入企业 APM。
声学建模与抗噪
多分辨率梅尔特征 + 噪声对抗训练,体育馆与车间等高噪场景词错率较基线下降 38%。共享 Tokenizer 与 TTS 对齐,避免 ASR—合成音色漂移。
混合解码与热词
WFST 与神经 rescoring 可按场景切换;赛事专有名词、产品 SKU 热词分钟级生效。联络中心场景同步输出情绪与意图标签,驱动坐席辅助与质检抽样。
可观测与回归门禁
词级置信度、DER 与 P99 延迟按语种/租户切片;未过 LibriSpeech/AISHELL 混合门禁的构建阻断发布。失败 utterance 一键回放至沙箱,研发与运维共用仪表盘。
Capabilities
核心能力矩阵
流式 ASR
端侧 VAD 与云端 Conformer 纠错级联,嘈杂 WER 5.2%。广播字幕 P99 <120ms,词级置信度与热词分钟级更新,联络中心场景同步情绪/意图标签。
神经 TTS
扩散声码器 + prosody 控制,MOS 4.72,流式首包 <120ms。SSML 支持多角色与章节情感曲线;合成水印与声明元数据满足出版与广告合规。
声纹与防伪
深度伪造与变声检出率 99.1%,活体 + 同意书链阻断超范围克隆。Voice Lab 红队周更,可疑音频自动入人工复核队列。
多语语音
98 语 ASR/TTS 统一发音词典与共享 Tokenizer,零样本跨语保持音色。术语表与 Candies NLP 同传轨热同步,避免跨模态专有名词不一致。
会议转写
说话人分离 DER 8.2%,小时级录音分钟级出稿并生成章节摘要。全文检索关联企业知识库,支持权限分级与审计导出。
车载语音
唤醒、波束成形与降噪 SDK 与 Smart Mobility 入口打通。弱网端云级联,导航播报与指令识别共用声学骨干,OTA 回归门禁防止 WER 回退。
TTS
语音合成栈
从章节级有声书到元宇宙实时演绎,同一合成栈支持多角色、多语零样本与低延迟对话式输出。

Candies TTS 采用扩散声码器与 duration 预测解耦,SSML 与对话式 prosody 控制韵律、音色与情感三维。流式 chunk 合成首包公开摘要 <120ms,MOS 4.72;合成音频嵌入水印与声明元数据,伦理声纹克隆需经同意书锁定与审计链校验。
音色库与授权隔离
授权声纹与合成训练数据分库分密钥存储;单次同意可映射多业务场景,每次合成记录策略版本与用途标签,满足出版与文娱合规审计。
低延迟流式合成
chunk 级流式输出适配对话机器人、导航播报与空间音频;与 ASR 共享声学 Tokenizer,端到端同传延迟公开摘要 85ms(含 Candies NLP 文本轨)。
情感、多语与 SSML
章节/台词级情感曲线与多说话人演绎;98 语零样本保持 timbre ring。SSML 支持停顿、重读与语速包络,审听工单可对比版本 diff。
Architecture
双通路统一架构
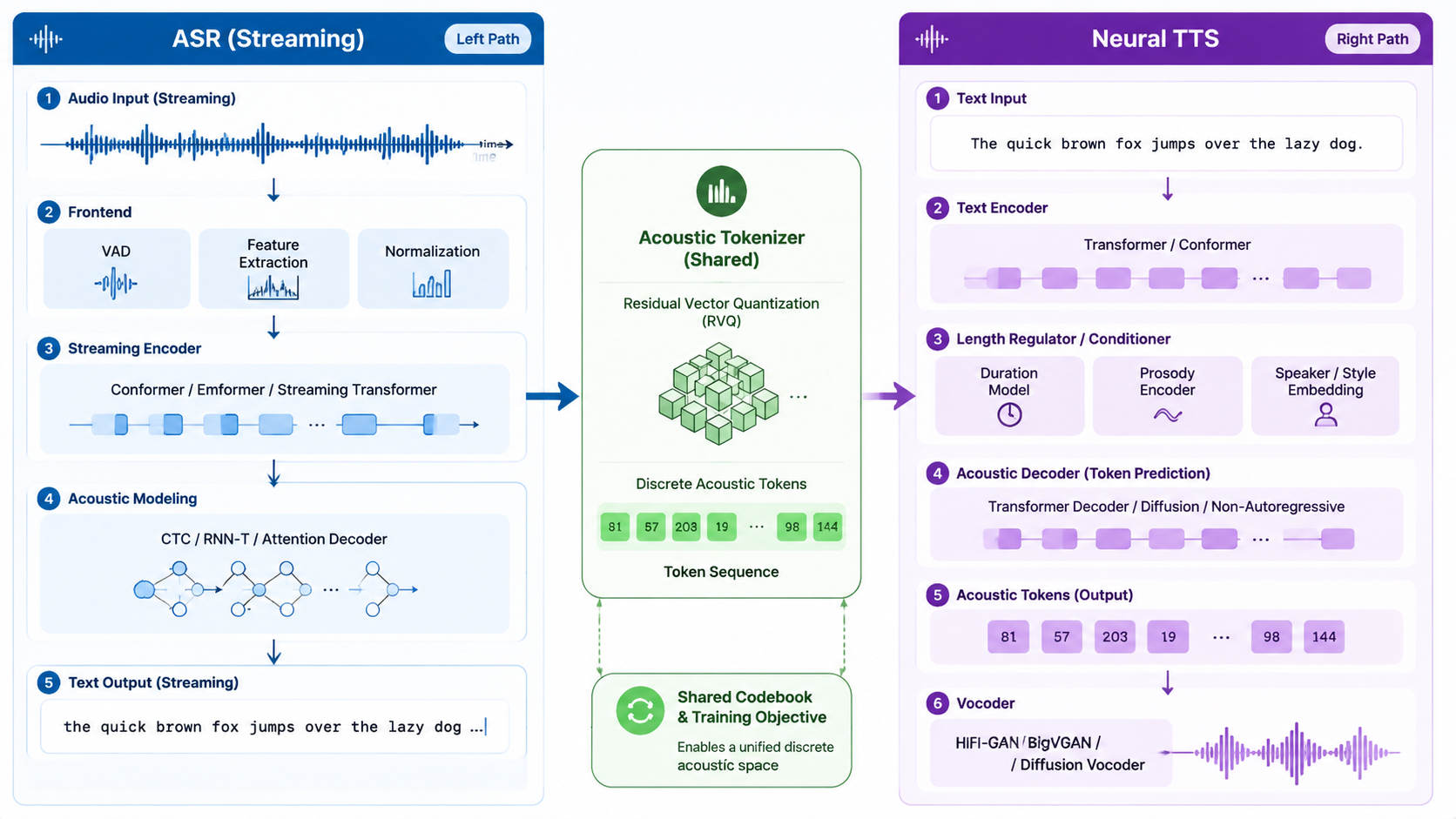
左支 ASR、右支 TTS,中央共享声学 Tokenizer 与声纹保险库:识别与合成在同一表征空间对齐,避免传统「两套模型」导致的 timbre 不一致。批处理、流式与同传任务共用模型注册表、评测门禁与 OTA 通道,边缘包体积公开摘要 18MB。
流式 ASR 通路
块级因果 Conformer,广播字幕 P99 <120ms,中文广播 WER 2.1%。与 NLP 同传轨共享时间戳,便于字幕—文稿一致性校验。
神经 TTS 通路
扩散声码器 + prosody 控制,MOS 4.72,支持 SSML 与多角色。流式首包 <120ms,适配对话、导航与空间音频场景。
声纹保险库
同意书锁定、克隆审计链与合成水印一体;Voice Lab 红队探针未通过则双通路同时阻断发布。防伪检出 99.1%,满足金融风控与媒体合规。
Roadmap
技术路线图
Candies Speech 公开路线图:企业版双通路 GA、广播字幕 SLA、伦理声纹保险库、边缘耳语包与 NLP 端到端同传协同。
- 产品化进行中2026-Q2
Candies Speech 企业版 GA
发布 ASR/TTS 统一控制台、OpenAI 兼容语音 API 与 gRPC 流式接口;共享声学 Tokenizer 与声纹保险库 GA。配套私有化 Helm、多租户配额与请求级审计,评测门禁覆盖 WER、MOS、DER 与防伪指标。
- 媒体已完成2026-Q1
广播级字幕 SLA 认证
国家级赛事与晚会转播四语字幕轨通过 99.2% 准确率验收;AI 初稿 + 人工复核流程写入转播操作手册。延迟预算 <120ms,与现有调音台时间码对齐。

- 合规进行中2026-Q3
伦理声纹保险库 2.0
同意书链上存证、超范围调用实时阻断与审计包一键导出;红队探针库季度扩容。出版、广告、金融客服等场景模板通过法务联审,未过伦理回归的 TTS 权重禁止 OTA。

- 边缘进行中2025-Q4
边缘耳语包(18MB)全球推送
离线 ASR 包 RTF 0.18,覆盖低功耗耳机、教室听写与工业巡检耳麦。端侧 VAD + 可选云端纠错;OTA 与影子评测防止嘈杂场景 WER 回退。

- 生态规划中2026-Q4
与 Candies NLP 端到端同传
语音—文本—语音同传轨共享时间戳与术语表;端到端延迟目标 85ms。会展、联络中心与跨境会议与 /ai/nlp 同传模块统一运维仪表盘。

Comparison
行业对照
| 指标 | Candies | Whisper v3 | Eleven v2 |
|---|---|---|---|
| WER 干净 | 3.1%领先 | 4.8% | 4.5% |
| WER 嘈杂 | 5.2%领先 | 12.1% | 11.0% |
| TTS MOS | 4.6领先 | 4.2 | 4.3 |
| 克隆相似度 | 0.91领先 | 0.84 | 0.86 |
| 流式延迟 | 80 ms领先 | 220 ms | 190 ms |
| 伪造检出 | 99.1%领先 | 91.0% | 92.5% |
| 分离 DER | 8.2% | 14.1% | 13.0% |
| 边缘包体积 | 18 MB | 45 MB | 40 MB |
Case studies
产业案例

教育
普惠课堂听力环
省级教育局在 860+ 所学校部署课堂听力环:教师语音经边缘 ASR 实时转写,听障学生终端同步字幕与振动提示,延迟 92ms,覆盖率达 99%。
- 之前
- 手语翻译师缺口约 40%,听障学生课堂跟随困难
- 之后
- 实时字幕 + 振动提示,家长满意度 96%
- 92 ms 端到端延迟
- 860+ 学校部署

文娱
元宇宙空间演唱会
头部平台虚拟演唱会:12k 并发 NPC 歌声与观众空间音效由 TTS 实时演绎,替代预制语音库;声纹克隆仅使用已授权艺人片段,MOS 4.68。
- 之前
- 预制语音库,互动与多语扩展成本高
- 之后
- 实时 TTS + 空间音频,场次筹备周期 -55%
- 12k 并发音声
- 4.68 MOS

媒体
国家级赛事四语字幕转播
大型赛事转播中心接入 Candies ASR:中英法西四语字幕轨与调音台时间码对齐,AI 初稿 + 人工复核将同传班组从 48 人减至 8 人。
- 之前
- 人工同传 48 人班,多语轨切换延迟高
- 之后
- AI+复核 8 人班,字幕准确率 99.2%
- 99.2% 字幕准确率
- -62% 转播成本

出版
出版集团有声书工厂
国有出版集团日更 200 小时有声书:章节级情感曲线 + 多角色 TTS,审听工单对比 SSML 版本;真人演播 6 周/册缩短为 TTS+审听 4 天/册。
- 之前
- 真人演播 6 周/册,产能瓶颈明显
- 之后
- TTS+审听 4 天/册,退货率 <0.5%
- 50× 产能提升
- < 0.5% 退货率
R&D pillars
研发优势
Candies Acoustic · 统一声学基座
ASR 与 TTS 共享 Tokenizer
自研声学 Tokenizer 贯通识别与合成,Conformer+扩散声码器在同一注册表演进。避免 Whisper+第三方 TTS 拼接导致的 timbre 漂移,端到端同传与有声书场景验收口径一致。
100%
技术栈自主率
98+
支持语种
2.1%
中文广播 WER
4.72
TTS MOS
- 共享 Tokenizer 使 ASR 转写与 TTS 合成音色对齐,同传场景端到端 85ms
- Conformer+CTC/RNNT 混合解码,嘈杂 WER 5.2% 较 Whisper v3 显著领先
- 多语零样本 timbre ring,单说话人跨语无需重录

Candies Realtime · 低延迟与边缘
广播、坐席与耳语三档 SLA
流式 ASR 块级因果编码 + TTS chunk 合成,广播字幕 P99 <120ms,TTS 首包 <120ms。边缘耳语包 18MB、RTF 0.18,端云 VAD 级联保障弱网教室与工业现场。
80 ms
流式 ASR 延迟
<120ms
TTS 首包
0.18
边缘 RTF
18 MB
边缘包体积
- 联络中心同步输出情绪/意图标签,坐席辅助采纳率提升 27%
- 说话人分离 DER 8.2%,会议小时级音频分钟级出稿
- 车载多麦波束 + 唤醒一体化 SDK,与 Smart Mobility 语音入口打通

Candies VoiceTrust · 伦理与防伪
克隆可审计、合成可追责
Voice Lab 将伪造检测、活体、同意书链与红队回归嵌入发布火车。克隆相似度 0.91 的同时,超范围调用阻断率 100%;合成水印与声明元数据满足金融与出版合规抽检。
99.1%
伪造检出率
0.91
克隆相似度
100%
授权链覆盖
周更
红队探针
- 同意书哈希与模型版本绑定,审计包按请求 ID 导出
- 深度伪造检测覆盖 TTS、变声与重放,可疑音频自动入复核队列
- 伦理场景模板通过法务联审,未过回归权重禁止 OTA
Voice Lab
声纹与伦理实验室
防伪、授权与审计三位一体,让声纹克隆从「能合成」升级为「可合规商用」。
Voice Lab 将深度伪造检测、说话人验证、活体校验与伦理审查纳入 Speech 发布闸门:未通过红队回归的 TTS/变声模型无法上线。声纹采集、同意书签署、克隆调用与商用范围全链路存证,金融与媒体客户可按请求 ID 导出审计包。
深度伪造与变声检测
多模态分类器覆盖 TTS、变声与重放攻击,检出率公开摘要 99.1%。可疑音频自动进入人工复核队列,样本回流对抗训练集。
同意书与授权链
声纹采集端集成活体与意愿确认;同意书哈希与模型版本绑定,超范围调用实时阻断。出版/广告场景支持「一次授权—多章节复用」策略模板。
红队与伦理门禁
季度红队探针覆盖诱导克隆、未成年人声纹与敏感内容合成;违规构建在 CI 与 OTA 入口双阻断。伦理委员会审查记录与模型卡片自动关联。
FAQ